Description
---
libraryname: sentence-transformers
pipelinetag: sentence-similarity
tags:
- feature-extraction
- sentence-similarity
- mteb
- transformers
- transformers.js
model-index:
- name: epoch0model
results:
- task:
type: Classification
dataset:
type: mteb/amazoncounterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.20895522388058
- type: ap
value: 38.57605549557802
- type: f1
value: 69.35586565857854
- task:
type: Classification
dataset:
type: mteb/amazonpolarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 91.8144
- type: ap
value: 88.65222882032363
- type: f1
value: 91.80426301643274
- task:
type: Classification
dataset:
type: mteb/amazonreviewsmulti
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 47.162000000000006
- type: f1
value: 46.59329642263158
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 24.253
- type: mapat10
value: 38.962
- type: mapat100
value: 40.081
- type: mapat1000
value: 40.089000000000006
- type: mapat3
value: 33.499
- type: mapat5
value: 36.351
- type: mrrat1
value: 24.609
- type: mrrat10
value: 39.099000000000004
- type: mrrat100
value: 40.211000000000006
- type: mrrat1000
value: 40.219
- type: mrrat3
value: 33.677
- type: mrrat5
value: 36.469
- type: ndcgat1
value: 24.253
- type: ndcgat10
value: 48.010999999999996
- type: ndcgat100
value: 52.756
- type: ndcgat1000
value: 52.964999999999996
- type: ndcgat3
value: 36.564
- type: ndcgat5
value: 41.711999999999996
- type: precisionat1
value: 24.253
- type: precisionat10
value: 7.738
- type: precisionat100
value: 0.98
- type: precisionat1000
value: 0.1
- type: precisionat3
value: 15.149000000000001
- type: precisionat5
value: 11.593
- type: recallat1
value: 24.253
- type: recallat10
value: 77.383
- type: recallat100
value: 98.009
- type: recallat1000
value: 99.644
- type: recallat3
value: 45.448
- type: recallat5
value: 57.965999999999994
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: vmeasure
value: 45.69069567851087
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: vmeasure
value: 36.35185490976283
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 61.71274951450321
- type: mrr
value: 76.06032625423207
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cossimpearson
value: 86.73980520022269
- type: cossimspearman
value: 84.24649792685918
- type: euclideanpearson
value: 85.85197641158186
- type: euclideanspearman
value: 84.24649792685918
- type: manhattanpearson
value: 86.26809552711346
- type: manhattanspearman
value: 84.56397504030865
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.25324675324674
- type: f1
value: 84.17872280892557
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: vmeasure
value: 38.770253446400886
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: vmeasure
value: 32.94307095497281
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 32.164
- type: mapat10
value: 42.641
- type: mapat100
value: 43.947
- type: mapat1000
value: 44.074999999999996
- type: mapat3
value: 39.592
- type: mapat5
value: 41.204
- type: mrrat1
value: 39.628
- type: mrrat10
value: 48.625
- type: mrrat100
value: 49.368
- type: mrrat1000
value: 49.413000000000004
- type: mrrat3
value: 46.400000000000006
- type: mrrat5
value: 47.68
- type: ndcgat1
value: 39.628
- type: ndcgat10
value: 48.564
- type: ndcgat100
value: 53.507000000000005
- type: ndcgat1000
value: 55.635999999999996
- type: ndcgat3
value: 44.471
- type: ndcgat5
value: 46.137
- type: precisionat1
value: 39.628
- type: precisionat10
value: 8.856
- type: precisionat100
value: 1.429
- type: precisionat1000
value: 0.191
- type: precisionat3
value: 21.268
- type: precisionat5
value: 14.649000000000001
- type: recallat1
value: 32.164
- type: recallat10
value: 59.609
- type: recallat100
value: 80.521
- type: recallat1000
value: 94.245
- type: recallat3
value: 46.521
- type: recallat5
value: 52.083999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 31.526
- type: mapat10
value: 41.581
- type: mapat100
value: 42.815999999999995
- type: mapat1000
value: 42.936
- type: mapat3
value: 38.605000000000004
- type: mapat5
value: 40.351
- type: mrrat1
value: 39.489999999999995
- type: mrrat10
value: 47.829
- type: mrrat100
value: 48.512
- type: mrrat1000
value: 48.552
- type: mrrat3
value: 45.754
- type: mrrat5
value: 46.986
- type: ndcgat1
value: 39.489999999999995
- type: ndcgat10
value: 47.269
- type: ndcgat100
value: 51.564
- type: ndcgat1000
value: 53.53099999999999
- type: ndcgat3
value: 43.301
- type: ndcgat5
value: 45.239000000000004
- type: precisionat1
value: 39.489999999999995
- type: precisionat10
value: 8.93
- type: precisionat100
value: 1.415
- type: precisionat1000
value: 0.188
- type: precisionat3
value: 20.892
- type: precisionat5
value: 14.865999999999998
- type: recallat1
value: 31.526
- type: recallat10
value: 56.76
- type: recallat100
value: 75.029
- type: recallat1000
value: 87.491
- type: recallat3
value: 44.786
- type: recallat5
value: 50.254
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 40.987
- type: mapat10
value: 52.827
- type: mapat100
value: 53.751000000000005
- type: mapat1000
value: 53.81
- type: mapat3
value: 49.844
- type: mapat5
value: 51.473
- type: mrrat1
value: 46.833999999999996
- type: mrrat10
value: 56.389
- type: mrrat100
value: 57.003
- type: mrrat1000
value: 57.034
- type: mrrat3
value: 54.17999999999999
- type: mrrat5
value: 55.486999999999995
- type: ndcgat1
value: 46.833999999999996
- type: ndcgat10
value: 58.372
- type: ndcgat100
value: 62.068
- type: ndcgat1000
value: 63.288
- type: ndcgat3
value: 53.400000000000006
- type: ndcgat5
value: 55.766000000000005
- type: precisionat1
value: 46.833999999999996
- type: precisionat10
value: 9.191
- type: precisionat100
value: 1.192
- type: precisionat1000
value: 0.134
- type: precisionat3
value: 23.448
- type: precisionat5
value: 15.862000000000002
- type: recallat1
value: 40.987
- type: recallat10
value: 71.146
- type: recallat100
value: 87.035
- type: recallat1000
value: 95.633
- type: recallat3
value: 58.025999999999996
- type: recallat5
value: 63.815999999999995
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 24.587
- type: mapat10
value: 33.114
- type: mapat100
value: 34.043
- type: mapat1000
value: 34.123999999999995
- type: mapat3
value: 30.45
- type: mapat5
value: 31.813999999999997
- type: mrrat1
value: 26.554
- type: mrrat10
value: 35.148
- type: mrrat100
value: 35.926
- type: mrrat1000
value: 35.991
- type: mrrat3
value: 32.599000000000004
- type: mrrat5
value: 33.893
- type: ndcgat1
value: 26.554
- type: ndcgat10
value: 38.132
- type: ndcgat100
value: 42.78
- type: ndcgat1000
value: 44.919
- type: ndcgat3
value: 32.833
- type: ndcgat5
value: 35.168
- type: precisionat1
value: 26.554
- type: precisionat10
value: 5.921
- type: precisionat100
value: 0.8659999999999999
- type: precisionat1000
value: 0.109
- type: precisionat3
value: 13.861
- type: precisionat5
value: 9.605
- type: recallat1
value: 24.587
- type: recallat10
value: 51.690000000000005
- type: recallat100
value: 73.428
- type: recallat1000
value: 89.551
- type: recallat3
value: 37.336999999999996
- type: recallat5
value: 43.047000000000004
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 16.715
- type: mapat10
value: 24.251
- type: mapat100
value: 25.326999999999998
- type: mapat1000
value: 25.455
- type: mapat3
value: 21.912000000000003
- type: mapat5
value: 23.257
- type: mrrat1
value: 20.274
- type: mrrat10
value: 28.552
- type: mrrat100
value: 29.42
- type: mrrat1000
value: 29.497
- type: mrrat3
value: 26.14
- type: mrrat5
value: 27.502
- type: ndcgat1
value: 20.274
- type: ndcgat10
value: 29.088
- type: ndcgat100
value: 34.293
- type: ndcgat1000
value: 37.271
- type: ndcgat3
value: 24.708
- type: ndcgat5
value: 26.809
- type: precisionat1
value: 20.274
- type: precisionat10
value: 5.361
- type: precisionat100
value: 0.915
- type: precisionat1000
value: 0.13
- type: precisionat3
value: 11.733
- type: precisionat5
value: 8.556999999999999
- type: recallat1
value: 16.715
- type: recallat10
value: 39.587
- type: recallat100
value: 62.336000000000006
- type: recallat1000
value: 83.453
- type: recallat3
value: 27.839999999999996
- type: recallat5
value: 32.952999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 28.793000000000003
- type: mapat10
value: 38.582
- type: mapat100
value: 39.881
- type: mapat1000
value: 39.987
- type: mapat3
value: 35.851
- type: mapat5
value: 37.289
- type: mrrat1
value: 34.455999999999996
- type: mrrat10
value: 43.909
- type: mrrat100
value: 44.74
- type: mrrat1000
value: 44.786
- type: mrrat3
value: 41.659
- type: mrrat5
value: 43.010999999999996
- type: ndcgat1
value: 34.455999999999996
- type: ndcgat10
value: 44.266
- type: ndcgat100
value: 49.639
- type: ndcgat1000
value: 51.644
- type: ndcgat3
value: 39.865
- type: ndcgat5
value: 41.887
- type: precisionat1
value: 34.455999999999996
- type: precisionat10
value: 7.843999999999999
- type: precisionat100
value: 1.243
- type: precisionat1000
value: 0.158
- type: precisionat3
value: 18.831999999999997
- type: precisionat5
value: 13.147
- type: recallat1
value: 28.793000000000003
- type: recallat10
value: 55.68300000000001
- type: recallat100
value: 77.99000000000001
- type: recallat1000
value: 91.183
- type: recallat3
value: 43.293
- type: recallat5
value: 48.618
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 25.907000000000004
- type: mapat10
value: 35.519
- type: mapat100
value: 36.806
- type: mapat1000
value: 36.912
- type: mapat3
value: 32.748
- type: mapat5
value: 34.232
- type: mrrat1
value: 31.621
- type: mrrat10
value: 40.687
- type: mrrat100
value: 41.583
- type: mrrat1000
value: 41.638999999999996
- type: mrrat3
value: 38.527
- type: mrrat5
value: 39.612
- type: ndcgat1
value: 31.621
- type: ndcgat10
value: 41.003
- type: ndcgat100
value: 46.617999999999995
- type: ndcgat1000
value: 48.82
- type: ndcgat3
value: 36.542
- type: ndcgat5
value: 38.368
- type: precisionat1
value: 31.621
- type: precisionat10
value: 7.396999999999999
- type: precisionat100
value: 1.191
- type: precisionat1000
value: 0.153
- type: precisionat3
value: 17.39
- type: precisionat5
value: 12.1
- type: recallat1
value: 25.907000000000004
- type: recallat10
value: 52.115
- type: recallat100
value: 76.238
- type: recallat1000
value: 91.218
- type: recallat3
value: 39.417
- type: recallat5
value: 44.435
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 25.732166666666668
- type: mapat10
value: 34.51616666666667
- type: mapat100
value: 35.67241666666666
- type: mapat1000
value: 35.78675
- type: mapat3
value: 31.953416666666662
- type: mapat5
value: 33.333
- type: mrrat1
value: 30.300166666666673
- type: mrrat10
value: 38.6255
- type: mrrat100
value: 39.46183333333334
- type: mrrat1000
value: 39.519999999999996
- type: mrrat3
value: 36.41299999999999
- type: mrrat5
value: 37.6365
- type: ndcgat1
value: 30.300166666666673
- type: ndcgat10
value: 39.61466666666667
- type: ndcgat100
value: 44.60808333333334
- type: ndcgat1000
value: 46.91708333333334
- type: ndcgat3
value: 35.26558333333333
- type: ndcgat5
value: 37.220000000000006
- type: precisionat1
value: 30.300166666666673
- type: precisionat10
value: 6.837416666666667
- type: precisionat100
value: 1.10425
- type: precisionat1000
value: 0.14875
- type: precisionat3
value: 16.13716666666667
- type: precisionat5
value: 11.2815
- type: recallat1
value: 25.732166666666668
- type: recallat10
value: 50.578916666666665
- type: recallat100
value: 72.42183333333334
- type: recallat1000
value: 88.48766666666667
- type: recallat3
value: 38.41325
- type: recallat5
value: 43.515750000000004
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 23.951
- type: mapat10
value: 30.974
- type: mapat100
value: 31.804
- type: mapat1000
value: 31.900000000000002
- type: mapat3
value: 28.762
- type: mapat5
value: 29.94
- type: mrrat1
value: 26.534000000000002
- type: mrrat10
value: 33.553
- type: mrrat100
value: 34.297
- type: mrrat1000
value: 34.36
- type: mrrat3
value: 31.391000000000002
- type: mrrat5
value: 32.525999999999996
- type: ndcgat1
value: 26.534000000000002
- type: ndcgat10
value: 35.112
- type: ndcgat100
value: 39.28
- type: ndcgat1000
value: 41.723
- type: ndcgat3
value: 30.902
- type: ndcgat5
value: 32.759
- type: precisionat1
value: 26.534000000000002
- type: precisionat10
value: 5.445
- type: precisionat100
value: 0.819
- type: precisionat1000
value: 0.11
- type: precisionat3
value: 12.986
- type: precisionat5
value: 9.049
- type: recallat1
value: 23.951
- type: recallat10
value: 45.24
- type: recallat100
value: 64.12299999999999
- type: recallat1000
value: 82.28999999999999
- type: recallat3
value: 33.806000000000004
- type: recallat5
value: 38.277
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 16.829
- type: mapat10
value: 23.684
- type: mapat100
value: 24.683
- type: mapat1000
value: 24.81
- type: mapat3
value: 21.554000000000002
- type: mapat5
value: 22.768
- type: mrrat1
value: 20.096
- type: mrrat10
value: 27.230999999999998
- type: mrrat100
value: 28.083999999999996
- type: mrrat1000
value: 28.166000000000004
- type: mrrat3
value: 25.212
- type: mrrat5
value: 26.32
- type: ndcgat1
value: 20.096
- type: ndcgat10
value: 27.989000000000004
- type: ndcgat100
value: 32.847
- type: ndcgat1000
value: 35.896
- type: ndcgat3
value: 24.116
- type: ndcgat5
value: 25.964
- type: precisionat1
value: 20.096
- type: precisionat10
value: 5
- type: precisionat100
value: 0.8750000000000001
- type: precisionat1000
value: 0.131
- type: precisionat3
value: 11.207
- type: precisionat5
value: 8.08
- type: recallat1
value: 16.829
- type: recallat10
value: 37.407000000000004
- type: recallat100
value: 59.101000000000006
- type: recallat1000
value: 81.024
- type: recallat3
value: 26.739
- type: recallat5
value: 31.524
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 24.138
- type: mapat10
value: 32.275999999999996
- type: mapat100
value: 33.416000000000004
- type: mapat1000
value: 33.527
- type: mapat3
value: 29.854000000000003
- type: mapat5
value: 31.096
- type: mrrat1
value: 28.450999999999997
- type: mrrat10
value: 36.214
- type: mrrat100
value: 37.134
- type: mrrat1000
value: 37.198
- type: mrrat3
value: 34.001999999999995
- type: mrrat5
value: 35.187000000000005
- type: ndcgat1
value: 28.450999999999997
- type: ndcgat10
value: 37.166
- type: ndcgat100
value: 42.454
- type: ndcgat1000
value: 44.976
- type: ndcgat3
value: 32.796
- type: ndcgat5
value: 34.631
- type: precisionat1
value: 28.450999999999997
- type: precisionat10
value: 6.241
- type: precisionat100
value: 0.9950000000000001
- type: precisionat1000
value: 0.133
- type: precisionat3
value: 14.801
- type: precisionat5
value: 10.280000000000001
- type: recallat1
value: 24.138
- type: recallat10
value: 48.111
- type: recallat100
value: 71.245
- type: recallat1000
value: 88.986
- type: recallat3
value: 36.119
- type: recallat5
value: 40.846
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 23.244
- type: mapat10
value: 31.227
- type: mapat100
value: 33.007
- type: mapat1000
value: 33.223
- type: mapat3
value: 28.924
- type: mapat5
value: 30.017
- type: mrrat1
value: 27.668
- type: mrrat10
value: 35.524
- type: mrrat100
value: 36.699
- type: mrrat1000
value: 36.759
- type: mrrat3
value: 33.366
- type: mrrat5
value: 34.552
- type: ndcgat1
value: 27.668
- type: ndcgat10
value: 36.381
- type: ndcgat100
value: 43.062
- type: ndcgat1000
value: 45.656
- type: ndcgat3
value: 32.501999999999995
- type: ndcgat5
value: 34.105999999999995
- type: precisionat1
value: 27.668
- type: precisionat10
value: 6.798
- type: precisionat100
value: 1.492
- type: precisionat1000
value: 0.234
- type: precisionat3
value: 15.152
- type: precisionat5
value: 10.791
- type: recallat1
value: 23.244
- type: recallat10
value: 45.979
- type: recallat100
value: 74.822
- type: recallat1000
value: 91.078
- type: recallat3
value: 34.925
- type: recallat5
value: 39.126
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 19.945
- type: mapat10
value: 27.517999999999997
- type: mapat100
value: 28.588
- type: mapat1000
value: 28.682000000000002
- type: mapat3
value: 25.345000000000002
- type: mapat5
value: 26.555
- type: mrrat1
value: 21.996
- type: mrrat10
value: 29.845
- type: mrrat100
value: 30.775999999999996
- type: mrrat1000
value: 30.845
- type: mrrat3
value: 27.726
- type: mrrat5
value: 28.882
- type: ndcgat1
value: 21.996
- type: ndcgat10
value: 32.034
- type: ndcgat100
value: 37.185
- type: ndcgat1000
value: 39.645
- type: ndcgat3
value: 27.750999999999998
- type: ndcgat5
value: 29.805999999999997
- type: precisionat1
value: 21.996
- type: precisionat10
value: 5.065
- type: precisionat100
value: 0.819
- type: precisionat1000
value: 0.11399999999999999
- type: precisionat3
value: 12.076
- type: precisionat5
value: 8.392
- type: recallat1
value: 19.945
- type: recallat10
value: 43.62
- type: recallat100
value: 67.194
- type: recallat1000
value: 85.7
- type: recallat3
value: 32.15
- type: recallat5
value: 37.208999999999996
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 18.279
- type: mapat10
value: 31.052999999999997
- type: mapat100
value: 33.125
- type: mapat1000
value: 33.306000000000004
- type: mapat3
value: 26.208
- type: mapat5
value: 28.857
- type: mrrat1
value: 42.671
- type: mrrat10
value: 54.557
- type: mrrat100
value: 55.142
- type: mrrat1000
value: 55.169000000000004
- type: mrrat3
value: 51.488
- type: mrrat5
value: 53.439
- type: ndcgat1
value: 42.671
- type: ndcgat10
value: 41.276
- type: ndcgat100
value: 48.376000000000005
- type: ndcgat1000
value: 51.318
- type: ndcgat3
value: 35.068
- type: ndcgat5
value: 37.242
- type: precisionat1
value: 42.671
- type: precisionat10
value: 12.638
- type: precisionat100
value: 2.045
- type: precisionat1000
value: 0.26
- type: precisionat3
value: 26.08
- type: precisionat5
value: 19.805
- type: recallat1
value: 18.279
- type: recallat10
value: 46.946
- type: recallat100
value: 70.97200000000001
- type: recallat1000
value: 87.107
- type: recallat3
value: 31.147999999999996
- type: recallat5
value: 38.099
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 8.573
- type: mapat10
value: 19.747
- type: mapat100
value: 28.205000000000002
- type: mapat1000
value: 29.831000000000003
- type: mapat3
value: 14.109
- type: mapat5
value: 16.448999999999998
- type: mrrat1
value: 71
- type: mrrat10
value: 77.68599999999999
- type: mrrat100
value: 77.995
- type: mrrat1000
value: 78.00200000000001
- type: mrrat3
value: 76.292
- type: mrrat5
value: 77.029
- type: ndcgat1
value: 59.12500000000001
- type: ndcgat10
value: 43.9
- type: ndcgat100
value: 47.863
- type: ndcgat1000
value: 54.848
- type: ndcgat3
value: 49.803999999999995
- type: ndcgat5
value: 46.317
- type: precisionat1
value: 71
- type: precisionat10
value: 34.4
- type: precisionat100
value: 11.063
- type: precisionat1000
value: 1.989
- type: precisionat3
value: 52.333
- type: precisionat5
value: 43.7
- type: recallat1
value: 8.573
- type: recallat10
value: 25.615
- type: recallat100
value: 53.385000000000005
- type: recallat1000
value: 75.46000000000001
- type: recallat3
value: 15.429
- type: recallat5
value: 19.357
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 47.989999999999995
- type: f1
value: 42.776314451497555
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 74.13499999999999
- type: mapat10
value: 82.825
- type: mapat100
value: 83.096
- type: mapat1000
value: 83.111
- type: mapat3
value: 81.748
- type: mapat5
value: 82.446
- type: mrrat1
value: 79.553
- type: mrrat10
value: 86.654
- type: mrrat100
value: 86.774
- type: mrrat1000
value: 86.778
- type: mrrat3
value: 85.981
- type: mrrat5
value: 86.462
- type: ndcgat1
value: 79.553
- type: ndcgat10
value: 86.345
- type: ndcgat100
value: 87.32
- type: ndcgat1000
value: 87.58200000000001
- type: ndcgat3
value: 84.719
- type: ndcgat5
value: 85.677
- type: precisionat1
value: 79.553
- type: precisionat10
value: 10.402000000000001
- type: precisionat100
value: 1.1119999999999999
- type: precisionat1000
value: 0.11499999999999999
- type: precisionat3
value: 32.413
- type: precisionat5
value: 20.138
- type: recallat1
value: 74.13499999999999
- type: recallat10
value: 93.215
- type: recallat100
value: 97.083
- type: recallat1000
value: 98.732
- type: recallat3
value: 88.79
- type: recallat5
value: 91.259
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 18.298000000000002
- type: mapat10
value: 29.901
- type: mapat100
value: 31.528
- type: mapat1000
value: 31.713
- type: mapat3
value: 25.740000000000002
- type: mapat5
value: 28.227999999999998
- type: mrrat1
value: 36.728
- type: mrrat10
value: 45.401
- type: mrrat100
value: 46.27
- type: mrrat1000
value: 46.315
- type: mrrat3
value: 42.978
- type: mrrat5
value: 44.29
- type: ndcgat1
value: 36.728
- type: ndcgat10
value: 37.456
- type: ndcgat100
value: 43.832
- type: ndcgat1000
value: 47
- type: ndcgat3
value: 33.694
- type: ndcgat5
value: 35.085
- type: precisionat1
value: 36.728
- type: precisionat10
value: 10.386
- type: precisionat100
value: 1.701
- type: precisionat1000
value: 0.22599999999999998
- type: precisionat3
value: 22.479
- type: precisionat5
value: 16.605
- type: recallat1
value: 18.298000000000002
- type: recallat10
value: 44.369
- type: recallat100
value: 68.098
- type: recallat1000
value: 87.21900000000001
- type: recallat3
value: 30.215999999999998
- type: recallat5
value: 36.861
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 39.568
- type: mapat10
value: 65.061
- type: mapat100
value: 65.896
- type: mapat1000
value: 65.95100000000001
- type: mapat3
value: 61.831
- type: mapat5
value: 63.849000000000004
- type: mrrat1
value: 79.136
- type: mrrat10
value: 84.58200000000001
- type: mrrat100
value: 84.765
- type: mrrat1000
value: 84.772
- type: mrrat3
value: 83.684
- type: mrrat5
value: 84.223
- type: ndcgat1
value: 79.136
- type: ndcgat10
value: 72.622
- type: ndcgat100
value: 75.539
- type: ndcgat1000
value: 76.613
- type: ndcgat3
value: 68.065
- type: ndcgat5
value: 70.58
- type: precisionat1
value: 79.136
- type: precisionat10
value: 15.215
- type: precisionat100
value: 1.7500000000000002
- type: precisionat1000
value: 0.189
- type: precisionat3
value: 44.011
- type: precisionat5
value: 28.388999999999996
- type: recallat1
value: 39.568
- type: recallat10
value: 76.077
- type: recallat100
value: 87.481
- type: recallat1000
value: 94.56400000000001
- type: recallat3
value: 66.01599999999999
- type: recallat5
value: 70.97200000000001
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 85.312
- type: ap
value: 80.36296867333715
- type: f1
value: 85.26613311552218
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: mapat1
value: 23.363999999999997
- type: mapat10
value: 35.711999999999996
- type: mapat100
value: 36.876999999999995
- type: mapat1000
value: 36.923
- type: mapat3
value: 32.034
- type: mapat5
value: 34.159
- type: mrrat1
value: 24.04
- type: mrrat10
value: 36.345
- type: mrrat100
value: 37.441
- type: mrrat1000
value: 37.480000000000004
- type: mrrat3
value: 32.713
- type: mrrat5
value: 34.824
- type: ndcgat1
value: 24.026
- type: ndcgat10
value: 42.531
- type: ndcgat100
value: 48.081
- type: ndcgat1000
value: 49.213
- type: ndcgat3
value: 35.044
- type: ndcgat5
value: 38.834
- type: precisionat1
value: 24.026
- type: precisionat10
value: 6.622999999999999
- type: precisionat100
value: 0.941
- type: precisionat1000
value: 0.104
- type: precisionat3
value: 14.909
- type: precisionat5
value: 10.871
- type: recallat1
value: 23.363999999999997
- type: recallat10
value: 63.426
- type: recallat100
value: 88.96300000000001
- type: recallat1000
value: 97.637
- type: recallat3
value: 43.095
- type: recallat5
value: 52.178000000000004
- task:
type: Classification
dataset:
type: mteb/mtopdomain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.0095759233926
- type: f1
value: 92.78387794667408
- task:
type: Classification
dataset:
type: mteb/mtopintent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 75.0296397628819
- type: f1
value: 58.45699589820874
- task:
type: Classification
dataset:
type: mteb/amazonmassiveintent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.45662407531944
- type: f1
value: 71.42364781421813
- task:
type: Classification
dataset:
type: mteb/amazonmassivescenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.07800941492937
- type: f1
value: 77.22799045640845
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: vmeasure
value: 34.531234379250606
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: vmeasure
value: 30.941490381193802
- task:
type: Reranking
dataset:
type: mteb/mindsmall
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.3115090856725
- type: mrr
value: 31.290667638675757
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map
value: 5.465
- type: map
value: 13.03
- type: map
value: 16.057
- type: map
value: 17.49
- type: map
value: 9.553
- type: map
value: 11.204
- type: mrr
value: 43.653
- type: mrr
value: 53.269
- type: mrr
value: 53.72
- type: mrr
value: 53.761
- type: mrr
value: 50.929
- type: mrr
value: 52.461
- type: ndcg
value: 42.26
- type: ndcg
value: 34.673
- type: ndcg
value: 30.759999999999998
- type: ndcg
value: 39.728
- type: ndcg
value: 40.349000000000004
- type: ndcg
value: 37.915
- type: precision
value: 43.653
- type: precision
value: 25.789
- type: precision
value: 7.754999999999999
- type: precision
value: 2.07
- type: precision
value: 38.596000000000004
- type: precision
value: 33.251
- type: recall
value: 5.465
- type: recall
value: 17.148
- type: recall
value: 29.768
- type: recall
value: 62.239
- type: recall
value: 10.577
- type: recall
value: 13.315
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map
value: 37.008
- type: map
value: 52.467
- type: map
value: 53.342999999999996
- type: map
value: 53.366
- type: map
value: 48.412
- type: map
value: 50.875
- type: mrr
value: 41.541
- type: mrr
value: 54.967
- type: mrr
value: 55.611
- type: mrr
value: 55.627
- type: mrr
value: 51.824999999999996
- type: mrr
value: 53.763000000000005
- type: ndcg
value: 41.541
- type: ndcg
value: 59.724999999999994
- type: ndcg
value: 63.38700000000001
- type: ndcg
value: 63.883
- type: ndcg
value: 52.331
- type: ndcg
value: 56.327000000000005
- type: precision
value: 41.541
- type: precision
value: 9.447
- type: precision
value: 1.1520000000000001
- type: precision
value: 0.12
- type: precision
value: 23.262
- type: precision
value: 16.314999999999998
- type: recall
value: 37.008
- type: recall
value: 79.145
- type: recall
value: 94.986
- type: recall
value: 98.607
- type: recall
value: 60.277
- type: recall
value: 69.407
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map
value: 70.402
- type: map
value: 84.181
- type: map
value: 84.796
- type: map
value: 84.81400000000001
- type: map
value: 81.209
- type: map
value: 83.085
- type: mrr
value: 81.02000000000001
- type: mrr
value: 87.263
- type: mrr
value: 87.36
- type: mrr
value: 87.36
- type: mrr
value: 86.235
- type: mrr
value: 86.945
- type: ndcg
value: 81.01
- type: ndcg
value: 87.99900000000001
- type: ndcg
value: 89.217
- type: ndcg
value: 89.33
- type: ndcg
value: 85.053
- type: ndcg
value: 86.703
- type: precision
value: 81.01
- type: precision
value: 13.336
- type: precision
value: 1.52
- type: precision
value: 0.156
- type: precision
value: 37.14
- type: precision
value: 24.44
- type: recall
value: 70.402
- type: recall
value: 95.214
- type: recall
value: 99.438
- type: recall
value: 99.928
- type: recall
value: 86.75699999999999
- type: recall
value: 91.44099999999999
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v
value: 56.51721502758904
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: vmeasure
value: 61.054808572333016
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 4.578
- type: mapat10
value: 11.036999999999999
- type: mapat100
value: 12.879999999999999
- type: mapat1000
value: 13.150999999999998
- type: mapat3
value: 8.133
- type: mapat5
value: 9.559
- type: mrrat1
value: 22.6
- type: mrrat10
value: 32.68
- type: mrrat100
value: 33.789
- type: mrrat1000
value: 33.854
- type: mrrat3
value: 29.7
- type: mrrat5
value: 31.480000000000004
- type: ndcgat1
value: 22.6
- type: ndcgat10
value: 18.616
- type: ndcgat100
value: 25.883
- type: ndcgat1000
value: 30.944
- type: ndcgat3
value: 18.136
- type: ndcgat5
value: 15.625
- type: precisionat1
value: 22.6
- type: precisionat10
value: 9.48
- type: precisionat100
value: 1.991
- type: precisionat1000
value: 0.321
- type: precisionat3
value: 16.8
- type: precisionat5
value: 13.54
- type: recallat1
value: 4.578
- type: recallat10
value: 19.213
- type: recallat100
value: 40.397
- type: recallat1000
value: 65.2
- type: recallat3
value: 10.208
- type: recallat5
value: 13.718
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cossimpearson
value: 83.44288351714071
- type: cossimspearman
value: 79.37995604564952
- type: euclideanpearson
value: 81.1078874670718
- type: euclideanspearman
value: 79.37995905980499
- type: manhattanpearson
value: 81.03697527288986
- type: manhattanspearman
value: 79.33490235296236
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cossimpearson
value: 84.95557650436523
- type: cossimspearman
value: 78.5190672399868
- type: euclideanpearson
value: 81.58064025904707
- type: euclideanspearman
value: 78.5190672399868
- type: manhattanpearson
value: 81.52857930619889
- type: manhattanspearman
value: 78.50421361308034
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cossimpearson
value: 84.79128416228737
- type: cossimspearman
value: 86.05402451477147
- type: euclideanpearson
value: 85.46280267054289
- type: euclideanspearman
value: 86.05402451477147
- type: manhattanpearson
value: 85.46278563858236
- type: manhattanspearman
value: 86.08079590861004
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cossimpearson
value: 83.20623089568763
- type: cossimspearman
value: 81.53786907061009
- type: euclideanpearson
value: 82.82272250091494
- type: euclideanspearman
value: 81.53786907061009
- type: manhattanpearson
value: 82.78850494027013
- type: manhattanspearman
value: 81.5135618083407
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cossimpearson
value: 85.46366618397936
- type: cossimspearman
value: 86.96566013336908
- type: euclideanpearson
value: 86.62651697548931
- type: euclideanspearman
value: 86.96565526364454
- type: manhattanpearson
value: 86.58812160258009
- type: manhattanspearman
value: 86.9336484321288
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cossimpearson
value: 82.51858358641559
- type: cossimspearman
value: 84.7652527954999
- type: euclideanpearson
value: 84.23914783766861
- type: euclideanspearman
value: 84.7652527954999
- type: manhattanpearson
value: 84.22749648503171
- type: manhattanspearman
value: 84.74527996746386
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cossimpearson
value: 87.28026563313065
- type: cossimspearman
value: 87.46928143824915
- type: euclideanpearson
value: 88.30558762000372
- type: euclideanspearman
value: 87.46928143824915
- type: manhattanpearson
value: 88.10513330809331
- type: manhattanspearman
value: 87.21069787834173
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cossimpearson
value: 62.376497134587375
- type: cossimspearman
value: 65.0159550112516
- type: euclideanpearson
value: 65.64572120879598
- type: euclideanspearman
value: 65.0159550112516
- type: manhattanpearson
value: 65.88143604989976
- type: manhattanspearman
value: 65.17547297222434
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cossimpearson
value: 84.22876368947644
- type: cossimspearman
value: 85.46935577445318
- type: euclideanpearson
value: 85.32830231392005
- type: euclideanspearman
value: 85.46935577445318
- type: manhattanpearson
value: 85.30353211758495
- type: manhattanspearman
value: 85.42821085956945
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 80.60986667767133
- type: mrr
value: 94.29432314236236
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 54.528
- type: mapat10
value: 65.187
- type: mapat100
value: 65.62599999999999
- type: mapat1000
value: 65.657
- type: mapat3
value: 62.352
- type: mapat5
value: 64.025
- type: mrrat1
value: 57.333
- type: mrrat10
value: 66.577
- type: mrrat100
value: 66.88
- type: mrrat1000
value: 66.908
- type: mrrat3
value: 64.556
- type: mrrat5
value: 65.739
- type: ndcgat1
value: 57.333
- type: ndcgat10
value: 70.275
- type: ndcgat100
value: 72.136
- type: ndcgat1000
value: 72.963
- type: ndcgat3
value: 65.414
- type: ndcgat5
value: 67.831
- type: precisionat1
value: 57.333
- type: precisionat10
value: 9.5
- type: precisionat100
value: 1.057
- type: precisionat1000
value: 0.11199999999999999
- type: precisionat3
value: 25.778000000000002
- type: precisionat5
value: 17.2
- type: recallat1
value: 54.528
- type: recallat10
value: 84.356
- type: recallat100
value: 92.833
- type: recallat1000
value: 99.333
- type: recallat3
value: 71.283
- type: recallat5
value: 77.14999999999999
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cossimaccuracy
value: 99.74158415841585
- type: cossimap
value: 92.90048959850317
- type: cossimf1
value: 86.35650810245687
- type: cossimprecision
value: 90.4709748083242
- type: cossimrecall
value: 82.6
- type: dotaccuracy
value: 99.74158415841585
- type: dotap
value: 92.90048959850317
- type: dotf1
value: 86.35650810245687
- type: dotprecision
value: 90.4709748083242
- type: dotrecall
value: 82.6
- type: euclideanaccuracy
value: 99.74158415841585
- type: euclideanap
value: 92.90048959850317
- type: euclideanf1
value: 86.35650810245687
- type: euclideanprecision
value: 90.4709748083242
- type: euclideanrecall
value: 82.6
- type: manhattanaccuracy
value: 99.74158415841585
- type: manhattanap
value: 92.87344692947894
- type: manhattanf1
value: 86.38497652582159
- type: manhattanprecision
value: 90.29443838604145
- type: manhattanrecall
value: 82.8
- type: maxaccuracy
value: 99.74158415841585
- type: maxap
value: 92.90048959850317
- type: maxf1
value: 86.38497652582159
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: vmeasure
value: 63.191648770424216
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: vmeasure
value: 34.02944668730218
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 50.466386167525265
- type: mrr
value: 51.19071492233257
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cossimpearson
value: 30.198022505886435
- type: cossimspearman
value: 30.40170257939193
- type: dotpearson
value: 30.198015316402614
- type: dotspearman
value: 30.40170257939193
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 0.242
- type: mapat10
value: 2.17
- type: mapat100
value: 12.221
- type: mapat1000
value: 28.63
- type: mapat3
value: 0.728
- type: mapat5
value: 1.185
- type: mrrat1
value: 94
- type: mrrat10
value: 97
- type: mrrat100
value: 97
- type: mrrat1000
value: 97
- type: mrrat3
value: 97
- type: mrrat5
value: 97
- type: ndcgat1
value: 89
- type: ndcgat10
value: 82.30499999999999
- type: ndcgat100
value: 61.839999999999996
- type: ndcgat1000
value: 53.381
- type: ndcgat3
value: 88.877
- type: ndcgat5
value: 86.05199999999999
- type: precisionat1
value: 94
- type: precisionat10
value: 87
- type: precisionat100
value: 63.38
- type: precisionat1000
value: 23.498
- type: precisionat3
value: 94
- type: precisionat5
value: 92
- type: recallat1
value: 0.242
- type: recallat10
value: 2.302
- type: recallat100
value: 14.979000000000001
- type: recallat1000
value: 49.638
- type: recallat3
value: 0.753
- type: recallat5
value: 1.226
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: mapat1
value: 3.006
- type: mapat10
value: 11.805
- type: mapat100
value: 18.146
- type: mapat1000
value: 19.788
- type: mapat3
value: 5.914
- type: mapat5
value: 8.801
- type: mrrat1
value: 40.816
- type: mrrat10
value: 56.36600000000001
- type: mrrat100
value: 56.721999999999994
- type: mrrat1000
value: 56.721999999999994
- type: mrrat3
value: 52.041000000000004
- type: mrrat5
value: 54.796
- type: ndcgat1
value: 37.755
- type: ndcgat10
value: 29.863
- type: ndcgat100
value: 39.571
- type: ndcgat1000
value: 51.385999999999996
- type: ndcgat3
value: 32.578
- type: ndcgat5
value: 32.351
- type: precisionat1
value: 40.816
- type: precisionat10
value: 26.531
- type: precisionat100
value: 7.796
- type: precisionat1000
value: 1.555
- type: precisionat3
value: 32.653
- type: precisionat5
value: 33.061
- type: recallat1
value: 3.006
- type: recallat10
value: 18.738
- type: recallat100
value: 48.058
- type: recallat1000
value: 83.41300000000001
- type: recallat3
value: 7.166
- type: recallat5
value: 12.102
- task:
type: Classification
dataset:
type: mteb/toxicconversations50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.4178
- type: ap
value: 14.648781342150446
- type: f1
value: 55.07299194946378
- task:
type: Classification
dataset:
type: mteb/tweetsentimentextraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 60.919637804187886
- type: f1
value: 61.24122013967399
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v
value: 49.207896583685695
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cossimaccuracy
value: 86.23114978840078
- type: cossimap
value: 74.26624727825818
- type: cossimf1
value: 68.72377190817083
- type: cossimprecision
value: 64.56400742115028
- type: cossimrecall
value: 73.45646437994723
- type: dotaccuracy
value: 86.23114978840078
- type: dotap
value: 74.26624032659652
- type: dotf1
value: 68.72377190817083
- type: dotprecision
value: 64.56400742115028
- type: dotrecall
value: 73.45646437994723
- type: euclideanaccuracy
value: 86.23114978840078
- type: euclideanap
value: 74.26624714480556
- type: euclideanf1
value: 68.72377190817083
- type: euclideanprecision
value: 64.56400742115028
- type: euclideanrecall
value: 73.45646437994723
- type: manhattanaccuracy
value: 86.16558383501221
- type: manhattanap
value: 74.2091943976357
- type: manhattanf1
value: 68.64221520524654
- type: manhattanprecision
value: 63.59135913591359
- type: manhattanrecall
value: 74.5646437994723
- type: maxaccuracy
value: 86.23114978840078
- type: maxap
value: 74.26624727825818
- type: maxf1
value: 68.72377190817083
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cossimaccuracy
value: 89.3681841114604
- type: cossimap
value: 86.65166387498546
- type: cossimf1
value: 79.02581944698774
- type: cossimprecision
value: 75.35796605434099
- type: cossimrecall
value: 83.06898675700647
- type: dotaccuracy
value: 89.3681841114604
- type: dotap
value: 86.65166019802056
- type: dotf1
value: 79.02581944698774
- type: dotprecision
value: 75.35796605434099
- type: dotrecall
value: 83.06898675700647
- type: euclideanaccuracy
value: 89.3681841114604
- type: euclideanap
value: 86.65166462876266
- type: euclideanf1
value: 79.02581944698774
- type: euclideanprecision
value: 75.35796605434099
- type: euclideanrecall
value: 83.06898675700647
- type: manhattanaccuracy
value: 89.36624364497226
- type: manhattanap
value: 86.65076471274106
- type: manhattanf1
value: 79.07408783532733
- type: manhattanprecision
value: 76.41102972856527
- type: manhattanrecall
value: 81.92947336002464
- type: maxaccuracy
value: 89.3681841114604
- type: maxap
value: 86.65166462876266
- type: maxf1
value: 79.07408783532733
license: apache-2.0
language:
- en
---
nomic-embed-text-v1.5: Resizable Production Embeddings with Matryoshka Representation Learning
Blog | Technical Report | AWS SageMaker | Nomic Platform
Exciting Update!: nomic-embed-text-v1.5 is now multimodal! nomic-embed-vision-v1.5 is aligned to the embedding space of nomic-embed-text-v1.5, meaning any text embedding is multimodal!
Usage
Important: the text prompt must include a task instruction prefix, instructing the model which task is being performed.
For example, if you are implementing a RAG application, you embed your documents as search_document: <text here> and embed your user queries as search_query: <text here>.
Notice: From transformers v5.5.0 and sentence transformers v5.3.0, trust_remote_code=True will no longer be necessary. This will only be possible with the text-only series as of now.
Task instruction prefixes
search_document
Purpose: embed texts as documents from a dataset
This prefix is used for embedding texts as documents, for example as documents for a RAG index.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5")
sentences = ['search_document: TSNE is a dimensionality reduction algorithm created by Laurens van Der Maaten']
embeddings = model.encode(sentences)
print(embeddings)search_query
Purpose: embed texts as questions to answer
This prefix is used for embedding texts as questions that documents from a dataset could resolve, for example as queries to be answered by a RAG application.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5")
sentences = ['search_query: Who is Laurens van Der Maaten?']
embeddings = model.encode(sentences)
print(embeddings)clustering
Purpose: embed texts to group them into clusters
This prefix is used for embedding texts in order to group them into clusters, discover common topics, or remove semantic duplicates.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5")
sentences = ['clustering: the quick brown fox']
embeddings = model.encode(sentences)
print(embeddings)classification
Purpose: embed texts to classify them
This prefix is used for embedding texts into vectors that will be used as features for a classification model
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5")
sentences = ['classification: the quick brown fox']
embeddings = model.encode(sentences)
print(embeddings)Sentence Transformers
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
matryoshka_dim = 512
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5")
sentences = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?']
embeddings = model.encode(sentences, convert_to_tensor=True)
embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))
embeddings = embeddings[:, :matryoshka_dim]
embeddings = F.normalize(embeddings, p=2, dim=1)
print(embeddings)Transformers
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
sentences = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?']
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1.5')
model.eval()
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
+ matryoshka_dim = 512
with torch.no_grad():
model_output = model(**encoded_input)
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
+ embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))
+ embeddings = embeddings[:, :matryoshka_dim]
embeddings = F.normalize(embeddings, p=2, dim=1)
print(embeddings)The model natively supports scaling of the sequence length past 2048 tokens. To do so,
- tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
+ tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased', model_max_length=8192)
- model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1.5')
+ rope_parameters = {"rope_theta": 1000.0, "rope_type": "dynamic", "factor": 2.0}
+ model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1.5', rope_parameters=rope_parameters)Transformers.js
import { pipeline, layer_norm } from '@huggingface/transformers';
// Create a feature extraction pipeline
const extractor = await pipeline('feature-extraction', 'nomic-ai/nomic-embed-text-v1.5');
// Define sentences
const texts = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?'];
// Compute sentence embeddings
let embeddings = await extractor(texts, { pooling: 'mean' });
console.log(embeddings); // Tensor of shape [2, 768]
const matryoshka_dim = 512;
embeddings = layer_norm(embeddings, [embeddings.dims[1]])
.slice(null, [0, matryoshka_dim])
.normalize(2, -1);
console.log(embeddings.tolist());Nomic API
The easiest way to use Nomic Embed is through the Nomic Embedding API.
Generating embeddings with the nomic Python client is as easy as
from nomic import embed
output = embed.text(
texts=['Nomic Embedding API', '#keepAIOpen'],
model='nomic-embed-text-v1.5',
task_type='search_document',
dimensionality=256,
)
print(output)For more information, see the API reference
Infinity
Usage with Infinity.
docker run --gpus all -v $PWD/data:/app/.cache -e HF_TOKEN=$HF_TOKEN -p "7997":"7997" \
michaelf34/infinity:0.0.70 \
v2 --model-id nomic-ai/nomic-embed-text-v1.5 --revision "main" --dtype float16 --batch-size 8 --engine torch --port 7997 --no-bettertransformerAdjusting Dimensionality
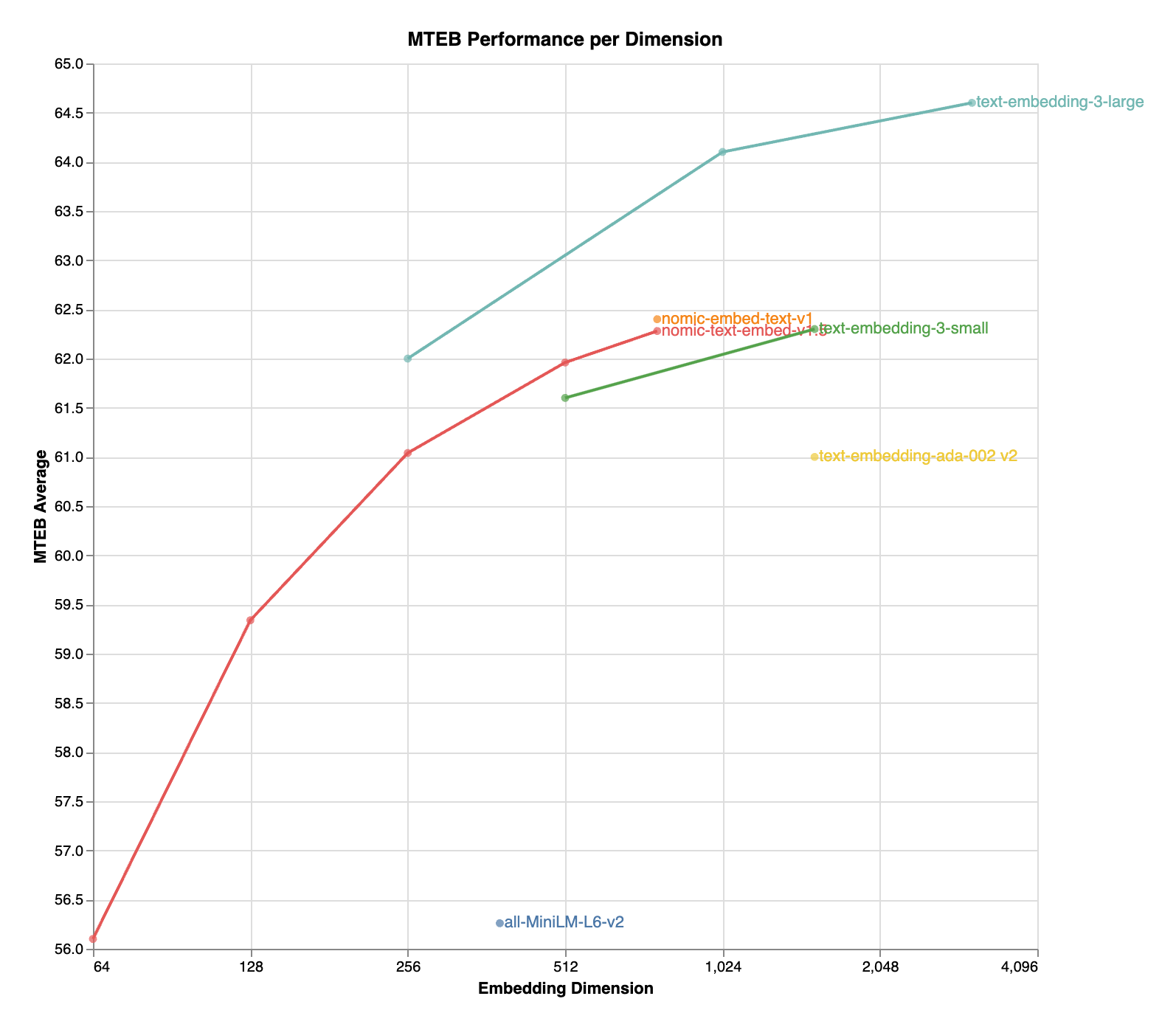
nomic-embed-text-v1.5 is an improvement upon Nomic Embed that utilizes Matryoshka Representation Learning which gives developers the flexibility to trade off the embedding size for a negligible reduction in performance.
| Name | SeqLen | Dimension | MTEB |
|---|---|---|---|
| nomic-embed-text-v1 | 8192 | 768 | 62.39 |
| nomic-embed-text-v1.5 | 8192 | 768 | 62.28 |
| nomic-embed-text-v1.5 | 8192 | 512 | 61.96 |
| nomic-embed-text-v1.5 | 8192 | 256 | 61.04 |
| nomic-embed-text-v1.5 | 8192 | 128 | 59.34 |
| nomic-embed-text-v1.5 | 8192 | 64 | 56.10 |
Training
Click the Nomic Atlas map below to visualize a 5M sample of our contrastive pretraining data!
We train our embedder using a multi-stage training pipeline. Starting from a long-context BERT model,
the first unsupervised contrastive stage trains on a dataset generated from weakly related text pairs, such as question-answer pairs from forums like StackExchange and Quora, title-body pairs from Amazon reviews, and summarizations from news articles.
In the second finetuning stage, higher quality labeled datasets such as search queries and answers from web searches are leveraged. Data curation and hard-example mining is crucial in this stage.
For more details, see the Nomic Embed Technical Report and corresponding blog post.
Training data to train the models is released in its entirety. For more details, see the contrastors repository
Join the Nomic Community
- Nomic: https://nomic.ai
- Discord: https://discord.gg/myY5YDR8z8
- Twitter: https://twitter.com/nomicai
Citation
If you find the model, dataset, or training code useful, please cite our work
@misc{nussbaum2024nomic,
title={Nomic Embed: Training a Reproducible Long Context Text Embedder},
author={Zach Nussbaum and John X. Morris and Brandon Duderstadt and Andriy Mulyar},
year={2024},
eprint={2402.01613},
archivePrefix={arXiv},
primaryClass={cs.CL}
}